
¿Cómo piensan las computadoras?
Como ingenieros o programadores estamos acostumbrados a que nuestros programas siempre sigan ciertas reglas o lógica, que podríamos decir de cierta manera son pasos para la realización de nuestros programas.
Pero cuando comenzamos en el mundo de la inteligencia artificial nos damos cuenta como estas reglas a las cuales estamos acostumbrados no se adaptan a problemas complejos, por ejemplo, ¿cómo resolverías la tarea de crear un traductor del idioma español a el inglés?
Suponiendo ese ejemplo rápidamente podríamos comenzar a modelar un programa que difícilmente pueda llevar a cabo esa tarea, probablemente imaginas una cantidad inimaginable de condicionales ‘if’, sin embargo, cuando pensemos en utilizar ese mismo programa para traducir entre dos idiomas diferentes, probablemente tendrías que reescribir todo ese programa, lo cual no sería una buena idea…
Desde el punto de vista de los datos que usemos para entrenar a nuestros agentes de inteligencia artificial, podemos aplicar tres técnicas según la naturaleza y disponibilidad de los datos.
- Aprendizaje supervisado.
- Aprendizaje no supervisado.
- Aprendizaje por refuerzo.
Aprendizaje supervisado (Supervised Machine Learning).
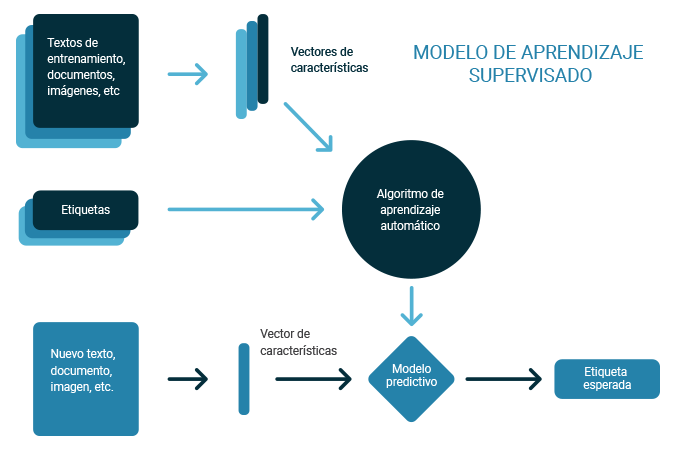 Figura 1. Diagrama del aprendizaje supervisado.
Figura 1. Diagrama del aprendizaje supervisado.
Si dentro de nuestro conjunto de datos podemos extraer con anticipación información precisa del resultado que esperamos, usaremos entonces aprendizaje supervisado. En los algoritmos de aprendizaje supervisado se genera un modelo predictivo, basado en datos de entrada y salida. La palabra clave “supervisado” viene de la idea de tener un conjunto de datos previamente etiquetado y clasificado, es decir, tener un conjunto de muestra, el cual ya se sabe a qué grupo, valor o categoría pertenecen los ejemplos. Algunos de los algoritmos de este tipo son los siguientes.
- K vecinos más próximos (K-nearest neighbors)
- Redes neuronales artificiales (Artificial neural networks)
- Máquinas de vectores de soporte (Support vector machines)
- Clasificador Bayesiano ingenuo (Naïve Bayes classifier)
- Árboles de decisión (Decision trees)
- Regresión logística (Logistic regression)
Aprendizaje no supervisado (Unsupervised Machine Learning)
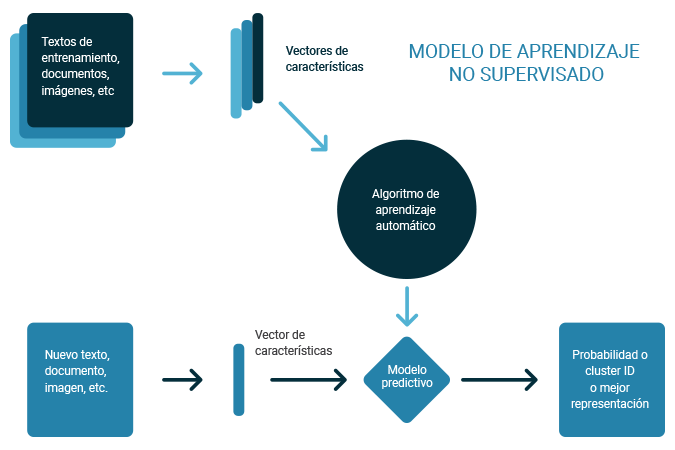 Figura 2. Diagrama del aprendizaje no supervisado.
Figura 2. Diagrama del aprendizaje no supervisado.
A diferencia del esquema anterior para los algoritmos de aprendizaje no supervisado no sabremos que esperar de nuestros datos, por lo cual buscaremos que sean los mismos datos los que describan sus relaciones y estructura, estos algoritmos son usados cuando tenemos relaciones ocultas entre nuestros datos y cuando no tenemos información adicional de los mismos.
Es decir, no se conoce ningún valor objetivo o de clase, ya sea categórico o numérico. El aprendizaje no supervisado está dedicado a las tareas de agrupamiento, también llamadas clustering o segmentación, donde su objetivo es encontrar grupos similares en el conjunto de datos.
Es decir, a diferencia del supervisado, los datos de entrada no están clasificados ni etiquetados, y no son necesarias estas características para entrenar el modelo..Entre los principales algoritmos de tipo no supervisado destacan:
- K-medias (K-means)
- Mezcla de Gaussianas (Gaussian mixtures)
- Agrupamiento jerárquico (Hierarchical clustering)
- Mapas auto-organizados (Self-organizing maps)
Aprendizaje por refuerzo (Reinforcement Learning)
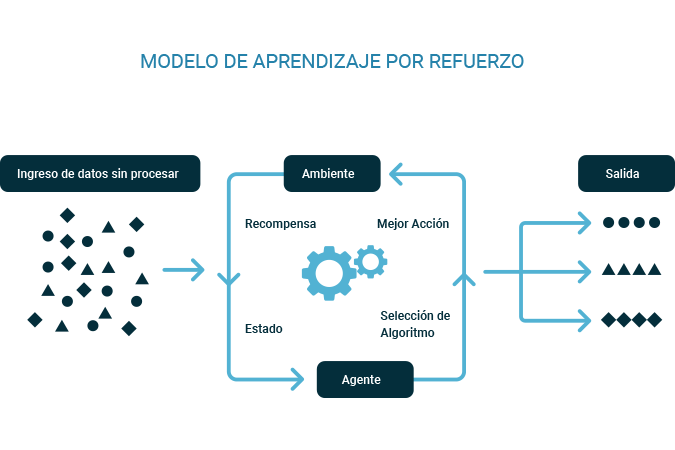 Figura 3. Diagrama del aprendizaje por refuerzo.
Figura 3. Diagrama del aprendizaje por refuerzo.
Por otro lado, cuando no contamos con información precisa sobre que esperamos como resultado, pero si podemos evaluar nuestros resultados, basados en si la decisión que el agente toma es buena o mala, podemos usar aprendizaje por refuerzo. Este tipo de aprendizaje es considerado un subtipo del aprendizaje supervisado.
Los algoritmos de aprendizaje por refuerzo definen modelos y funciones enfocadas en maximizar una medida de “recompensas”, basados en “acciones” y al ambiente en el que el agente inteligente se desempeñará. Algunos algoritmos de aprendizaje por refuerzo son:
- Programación dinámica (Dynamic programming)
- Q-learning
- SARSA
Ningún algoritmo es mejor que el otro, cada tipo de aprendizaje tiene sus ventajas y desventajas dependiendo de nuestros datos. En machine learning estas son solo algunas de las posibles ramas que se tienen para la inteligencia artificial, dependerá de nosotros determinar nuestro problema para aplicar el algoritmo que mejor aproxime nuestra solución buscada.
Pero si nuestro problema no encaja con alguna de estas tres principales clasificaciones podríamos pensar en algoritmos del siguiente tipo:
- Algoritmos evolutivos: Para problemas de optimización, problemas que pueden ser expresados como una función matemática.
- Lógica difusa: Problemas lógicos donde lo que entra en juego son variables continuas.
- Agentes: Problemas donde queremos modelar entornos compuestos con diferentes agentes que interactúen entre sí.
- Sistemas expertos: Problemas donde se pueda generar sistemas de reglas para responder preguntas concretas.


{kind=link}